

Security metrics to help protect against ransomware

Andrew Jaquith
read
Andrew Jaquith walks us through a three-step playbook of ransomware protection metrics to help security teams disrupt the bad guys and reduce the chances of a successful ransomware attack. We’re taking a little detour from our usual deep dive into a single security metric and enlisting the help of Andrew, a seasoned CISO and security metrics expert, who currently spends his days as CISO of QOMPLX helping his customers defend against cyber threats, specifically ransomware. Board members across the world are seeing headlines in the Financial Times or the Economist, and are asking if the same can happen to them. As they become more cyber-savvy, boards take interest and apply more scrutiny to security metrics and measurement, perhaps even focusing on the current risk du jour. But ransomware protection is something that security pros have been thinking about and actively trying to combat since 1989.
I spend a significant part of my day job thinking about ransomware. It’s relatively simple. The bad guys have a three-step playbook: 1. Get in. 2. Spread. 3. Profit.
Measuring with ransomware protection in mind
"I spend a significant part of my day job thinking about ransomware", says Andrew. "It’s relatively simple. The bad guys have a three-step playbook:"
- "Get in."
- "Spread."
- "Profit."
At each point, there’s something they need to achieve before they get to the next step. Equally, says Andrew, "you also have opportunities to prevent. And that is where the measurement opportunity comes in." By establishing a set of security metrics and measurements with ransomware in mind, you are taking a proactive approach to reduce the risk of ransomware.
Step 1: Get in - External facing ransomware protection metrics
There are a few classic ways of getting ransomware into an organisation.
The bad guys are going to size you up. It’s like walking down the street and rattling doorknobs. If one is loose, they’ll try to break in.
Ransomware actors need an initial point of ingress. They may exploit an external weakness, such as a vulnerable VPN gateway or an unpatched server. Or they phish an employee to try and get them to download malicious software onto a ‘beachhead’ machine. First, consider how you measure external security posture. How does your organisation look from the outside? "The bad guys are going to size you up. It’s like walking down the street and rattling doorknobs. If one is loose, they’ll try to break in." To counter, defenders need to measure their 'known bads' – external exposures and significant weaknesses. Andy gives some examples: a VPN server without two-factor authentication protecting the administrative portal; a remote desktop protocol port open. Are any of your employees found in ‘darkweb’ repos containing breached usernames and passwords? In addition, there’s basic hygiene stuff, DNS records, email security, the presence of SSL v3 encryption, and so on. Andy recommends keeping a list of these ‘known bads’ that attackers will seek out, and ensure your perimeter has zero. There’s another hugely important element to highlight here – how you measure patching. Particularly when it comes to critical services such as external-facing assets and core data centres. If you have an asset that isn’t up to patch, "that’s one way the bad guys are going to take advantage," says Andrew. The problem is that in production, the prevailing attitude is: if it’s working, don’t touch it. That means that operationally, people don’t push patches out as quickly as they perhaps should. It’s understandable that patching can get behind, but critical patches should be pushed out within 72 hours as a reasonable SLA. "If the vulnerability in question is high severity, and there are exploits circulating in the world being actively abused, you want to get those patches out as soon as you can." Then there are phishing metrics. Many CISOs advocate reporting successful phishing tests as a leading indicator of how resilient employees are to phishing. But not all phishing metrics are especially diagnostic. "I do not recommend phishing metrics", says Andrew. "I think some CISOs report phishing metrics to the board because they don’t have a better alternative. Anti-phishing testing is necessary, but in my experience they test the skill of the phisher more than the gullibility of the phished employees. My former boss Phil [Venables] likes to say: ‘people want to click; that’s what they do’. So it isn’t surprising that a highly skilled phisher will get somebody to fall for a fake email. Some are so good that if you’re specifically targeted, you don’t really have a chance." The most valuable metric to measure about phishing, says Andrew, relates to completeness – the percentage of employees who are timely on their testing.  The first step in your defence is maintaining a good security posture. Eliminate the obvious 'known bads', ensure your patching is good, and try your best not to get phished.
The first step in your defence is maintaining a good security posture. Eliminate the obvious 'known bads', ensure your patching is good, and try your best not to get phished.
Step 2: Spread - Metrics to reduce the risk of ransomware propagating
As a rough rule of thumb, I like to see one or two domain admins per 1000 full-time equivalents. But if you have 50 DAs per 1000, one of them is bound to have a guessable or crackable password – and we’ve all seen what happens next.
Assume an attacker has ‘gotten in’ and has compromised an endpoint. The attacker’s next step, in Andrew’s experience, is to try to "gain domain dominance on the Windows network so they can start pushing ransomware out very rapidly and lock the place up. That’s what turns minor compromises into big ones." One of the key indicators to monitor is privilege concentration. Specifically, Andrew suggests measuring how many Active Directory domain administrators you have. "As a rough rule of thumb, I like to see one or two domain admins per 1000 full-time equivalents," says Andrew, giving a solid baseline. ‘But if you have 50 DAs per 1000, one of them is bound to have a guessable or crackable password – and we’ve all seen what happens next’. Another valuable ransomware protection metric to measure is valid authentication traffic. This means monitoring the integrity of authentication protocols to validate that "each person bearing credentials is who they say they are, and not some bad guy that obtained forged credentials by running an attack tool." Indeed, Andy’s company QOMPLX has a range of products that specifically combat this problem. Organisations should also measure valid authorisations, such as outbound Windows domain trusts that allow administrative privileges to be trusted across organisational boundaries. This is especially important for organisations involved in mergers and acquisitions. "Suppose you’ve acquired a small subsidiary in Honduras. They have their own Windows domain, but it might not make business sense to rebuild their desktop and server infrastructure to match headquarters. The CIO may feel it’s more expedient to just leave the existing Windows network in place, and trust that domain. The difficulty is that you are trusting the credentials of those administrators in Honduras. What if they have a guessable or brute-forceable password? If a subsidiary you trust gets popped, the attacker can take over the whole network. So, you need to look for how many of those outbound privileged trusts exist that facilitate a pathway for attack." Lastly, Andrew recommends measuring the security of Windows service accounts, which are used to run server-based software, as they typically have elevated privileges. "The naïve way to do service accounts is to give them dumb passwords that are easily guessable and do not change. Some companies do this to avoid production outages, or to ensure that ‘institutional memory’ isn’t lost if staff change. Fortunately, recent versions of Active Directory give IT staff the ability to use managed service accounts in many cases. Windows then takes care of automatic password rotation and complexity, so they won’t be guessed or brute-forced. Managed service accounts can radically decrease your risk," says Andrew.  If the bad guys are inside, you want it to be hard for them to propagate. Ensure your privileges are tight, your service accounts are managed, and you have a handle on authentication.
If the bad guys are inside, you want it to be hard for them to propagate. Ensure your privileges are tight, your service accounts are managed, and you have a handle on authentication.
Step 3: Profit - Metrics to help you recover from a ransomware attack
If somebody's already gotten in and spread ransomware all over the company, you've got bigger problems than your ability to measure it... the recovery is really where the rubber meets the road, because if you can’t recover, you’re done.
"If somebody's already gotten in and spread ransomware all over the company, you've got bigger problems than your ability to measure it." From a security standpoint, the two most important objectives are to ensure that you are protecting your most sensitive operational and customer data, and that you have the ability to recover from an attack. As Andy put it, "the recovery is really where the rubber meets the road, because if you can’t recover, you’re done." Your ‘crown jewels’ data is attractive to attackers because it gives them something to ransom, leak or destroy if their demands are not met. "Few good metrics exist to measure whether you have put these out of the reach of attackers," says Andrew. Nonetheless, your metrics should focus on the completeness of your ‘crown jewels’ inventory: what they are, who owns them, and a score for the resiliency of each asset based on whether each asset owner has a plan for resiliency, is backing up the assets regularly, and is periodically testing the ability to recover from an outage. Successful tests here suggest you have a backup strategy in the documentation and the processes are worked out and established. This type of recovery test is most important for Windows Active Directory. Another strategy is to measure how many of your backups are written to immutable storage. "Take the example of Amazon S3 – it allows you to write your backups and store them in a backup that can’t be deleted. Ransomware attackers may look to delete your backups as part of their attack chain, so immutable storage helps to prevent that."  Proactively measure things that indicate your ability to recover from a ransomware attack. Focus on your critical assets and get backup your backups.
Proactively measure things that indicate your ability to recover from a ransomware attack. Focus on your critical assets and get backup your backups.
Ransomware protection metrics dashboard
So, to put all this into perspective, we’ve created a mock ransomware protection metrics dashboard. This dashboard is designed to tell a story that security teams can report to a board if asked about the security threat du jour – ransomware. The story is similar to what we have been talking about in this article. It covers the three objectives of the attacker, and some of the key measures you have in preventing them from getting to the next step. 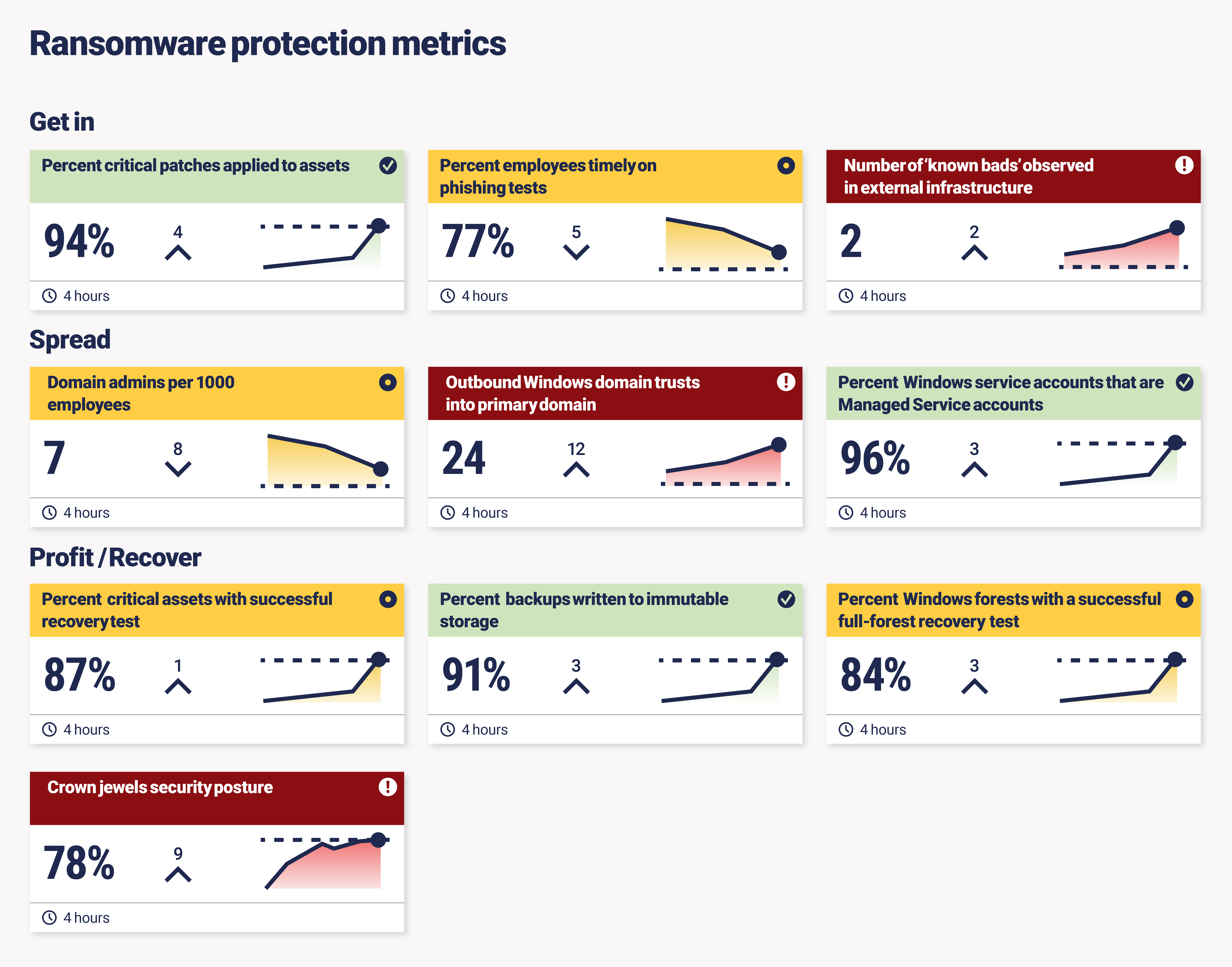
How can Continuous Controls Monitoring support ransomware protection?
So, you have all your anti-ransomware controls in place. You’re measuring your ransomware protection metrics. But, how sure are you that they’re working as expected? It takes multiple control failures for a ransomware attack to be successful. Each layer – Get in, Spread, Profit – is susceptible to control failures. If you’re the victim of a successful ransomware attack, it’s because the controls you have set up to defend against that ransomware attack have failed at several points. You need to ensure your controls are operating as expected, always. Enter Continuous Controls Monitoring – an emerging category in security and risk that helps you to ensure your controls are deployed as expected and automates your security metrics and measurement around those controls. CCM can help to reduce a variety of risks across your cybersecurity defenses by ensuring your controls are working effectively across the key areas of ransomware protection. It supports the basics around security posture, such as controls coverage (around all controls, not just phishing), asset inventory, identifying critical assets, or how attackers propagate around the environment through privileged access management. But it also facilitates a much more advanced security programme that will allow custom reporting around specific areas of interest to an individual organisation, in this case: ransomware protection.
If you'd like to find out more about how Panaseer can give you visibility over your cybersecurity controls request a demo and subscribe to Metric of the Month for content straight to your inbox.
About the author
Andrew Jaquith
Related blogs

Three measurement essentials for reporting cybersecurity to the board