

How to measure mean time to detect and respond metrics

Matt Burns
read
In this instalment of Metric of the Month, we are delighted to welcome Matt Burns as a guest author to talk about 'mean time to detect and respond'. Matt has over a decade of experience in security and risk, and currently works for the PwC UK Cyber Security Practice as a trusted advisor to boards and senior management in the ever-changing and highly regulated world that is the Financial Services sector.  Straight off the bat, I’m going to hit you with some controversy. I know that usually in the Metric of the Month series, people will talk about how important and valuable a particular metric is. But, in this article, I’m going to talk about how ‘mean time to detect and respond’ can be a double-edged sword. While it can be a necessary and valuable thing to measure, it can also cause some headaches.
Straight off the bat, I’m going to hit you with some controversy. I know that usually in the Metric of the Month series, people will talk about how important and valuable a particular metric is. But, in this article, I’m going to talk about how ‘mean time to detect and respond’ can be a double-edged sword. While it can be a necessary and valuable thing to measure, it can also cause some headaches.
What is mean time to detect and respond?
Defending against attackers is a race against time. The longer an attacker has in your network, the greater the potential impact.
Fundamentally you are measuring the time it takes to detect a vulnerability that could be exploited (from the moment it is known) or a threat event that could cause impact (from the moment the attacker gained a foothold on the network), and respond to contain it. The ultimate objective is to drive down the time it takes to detect and respond to an attack to zero (or as close to). That’s something every security organisation wants to achieve. The ‘mean time to detect and respond’ metric is a measure of how effective your security operations team is at achieving that goal. It’s really important to measure this metric because defending against attackers is a race against time. The longer an attacker has in your network, the greater the potential impact. In 2020, the average time to identify and contain a breach was 280 days, according to the IBM Security Cost of a Data Breach Report 2020. So, you want to get that time down by keeping on top of events. It’s also an essential metric that measures the maturity of capability in the NIST framework, relating to two of the key functions – detect and respond; as well as CIS controls 6 - Maintenance, Monitoring and Analysis of Audit Logs, and 19 – incident response and management.
So, ‘mean time’ can be pretty worthless without an additional quality control or assurance metric on tickets closed to check that people are doing the right thing.
Mean time to detect and respond can be used as a simple timeliness metric, but ‘mean time’ can drive some wrong behaviours. If there is a mean target above someone’s head, it can drive them to potentially unhelpful behaviour in order to achieve it. This is particularly the case when working with a third party. For example, people might close tickets to hit their mean, improve their numbers, and get paid, even if the quality of the work on that ticket might suffer. So, ‘mean time’ can be pretty worthless without an additional quality control or assurance metric on tickets closed to check that people are doing the right thing.
What are the challenges with measuring time to detect and respond?
We have already covered the main challenge with this metric – primarily that it can drive some wrong behaviours. There are further challenges, though. For example, it is important to note the scope of events (and their associated use cases and log sources) detected. Not all organisations include all types of events in this metric, such as data-loss events, privileged access monitoring events, or physical security events (that could lead to an IT-related event). Also it’s important to understand that not all events are born equal. We need to understand the context of the potential threat, the systems affected, and develop and execute responses strategies accordingly not purely based on time but the best outcome. Without doing this we run the risk of the response team making hasty decisions and missing vital information that could increase the success of their containment actions.
Who is interested in time to detect and respond metrics?
When we are talking about what makes a good security metric, audience is really important. In this case, there are several important audiences for mean time to detect and respond. First is the blue team. These are the defenders – they need to see the metric and use it as a baseline to which they can tune their operations. Next is the red team. The ‘ethical hackers’ need to simulate attacks that push the defenders to maintain efficiency and effectiveness of operations. These stress tests help the blue team to improve and optimise their processes. Finally, senior management and/or the board. Improving your mean time to detect is a good way to demonstrate the effectiveness of security operations to management, but on the other side of that, it can also be a measure by which management can oversee and challenge the blue team’s performance.
How do you effectively measure detect and respond times?
This question has a few parts. One part is using the metric in a ‘good’ way – so rather than to drive behaviours, it is much better used as a baseline.
24 hours is a reasonable baseline to start with and then reduce over time. Mean time to detect – 12 hours. Mean time to respond (and contain) – 12 hours.
The second is about what is a ‘good’ number. Again, there are a few ways to think about it. How long it takes the attacker to get in. And then, how long it takes them to reach their objective and get out. One person’s ‘mean’ is never really the same as another’s. Comparisons across industry are very difficult. Generally, though, 24 hours is a reasonable baseline to start with and then reduce over time. Mean time to detect – 12 hours. Mean time to respond (and contain) – 12 hours. Here's a mock dashboard to see how that might look: 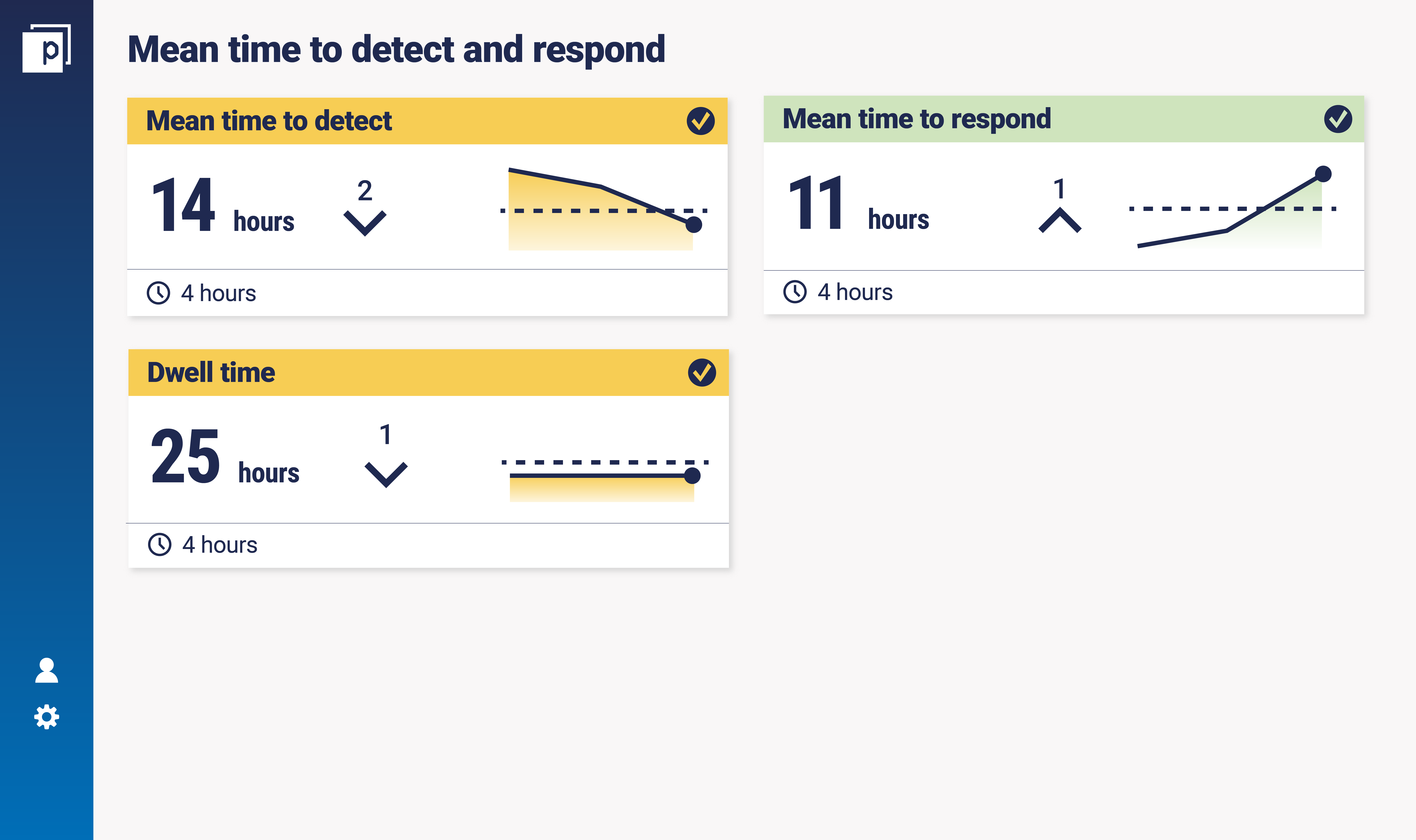 To illustrate the importance of this, let’s take a simple example of when it goes wrong in the realm of business email compromise. An attacker gains access to the corporate email system. They manage to subvert a member of the treasury team’s senior management into making a one-off payment into an account of their choice. The security operations team identifies a number of unusual login events on a treasury team account, such as a midnight login. But other more seemingly important events are being responded to – users are clicking on links and downloading malware to devices, so the security operations team goes to investigate (even if these problems may be mitigated by AV or EDR). 38 hours after the treasury team email accounts were compromised by the attacker, the senior manager approved the payment.
To illustrate the importance of this, let’s take a simple example of when it goes wrong in the realm of business email compromise. An attacker gains access to the corporate email system. They manage to subvert a member of the treasury team’s senior management into making a one-off payment into an account of their choice. The security operations team identifies a number of unusual login events on a treasury team account, such as a midnight login. But other more seemingly important events are being responded to – users are clicking on links and downloading malware to devices, so the security operations team goes to investigate (even if these problems may be mitigated by AV or EDR). 38 hours after the treasury team email accounts were compromised by the attacker, the senior manager approved the payment.
What should we set a mean time to be?
As described above, industries broadly say that 24 hours is a useful baseline for mean time to detect and respond. If this were the case for this organisation, they would have, prior to this event, tuned and correlated their rules to try and meet this objective, and, potentially, responded to this event. In real life, it can be much more complicated, but this makes the point – mean time to detect is an essential baseline measurement.
If the first thing you do is jump on the ‘mean’ band wagon, you might fall into the ‘bad behaviour’ rut.
What’s the best way to start measuring time to detect and respond?
If the first thing you do is jump on the ‘mean’ band wagon, you might fall into the ‘bad behaviour’ rut. Perhaps even better would be, instead of looking at mean, looking at mode. Going back to the challenges above, modal analysis would help you stack rank events and help you target where specific events that took a long time fell outside the mean average, allowing the defender to focus on root cause analysis and continuous improvement. But moving away from timeliness, the first thing you need to do is focus on ‘accuracy’ and ‘coverage’. Understand what threats you have, what data you need to identify those threats, and develop metrics that focus on coverage of that data across the estate. Then try to improve the accuracy of your events, i.e., working to reduce false positives. And then move on to temporal analysis, using both the mean baseline and the mode. If you start with the mean, you’ll miss out on the fundamentals. We mentioned in the introduction an accompanying quality assurance metric. It’s necessary, but unfortunately a manual process. It looks at a percentage of samples on tickets that pass a satisfaction test, measuring what a user saw and whether they took an appropriate response according to your organisation’s playbook or checklist. That quality review helps to improve the behaviours of the responder. It also serves as a quality feedback loop you can measure, in the case of an issue with the detection systems. It can help to tune out false positives and improve detection rule correlation or models i.e. where an event could have had relevant contextual information linked with it to increase its criticality, such as the age of the domain where the external IP originated from, or where a new internal connection never made before was not identified by a behavioural model.
Where does Continuous Controls Monitoring bring value?
Continuous Controls Monitoring (CCM) can bring confidence to security and business leaders that cyber defenses are keeping pace with adversary advances, if the measures have been well designed – i.e. actionable and presented with context and assurance – as per the above.
I don’t care if someone is attacking a firewall, but if someone is attacking the payments process, that’s extremely valuable to know.
In order to be as effective as possible, it needs to be populated with good data from a variety of sources, and a strong design and implementation. When this is achieved, CCM provides risk and business context, relatable to the risks the business faces, correlated to important parts of the business. I don’t care if someone is attacking a firewall, but if someone is attacking the payments process, that’s extremely valuable to know.
The importance of detect and respond metrics?
Cybersecurity is often a race against time. That means measuring and improving your mean time to detect and respond to threats and vulnerabilities is essential to maintaining a solid security programme and seeing how well your security team is performing. However, we need to be mindful that it is not the only measure of importance. Don't let poor behaviours (i.e. prioritising speed and volume over quality) get in the way. It should be used as a baseline, not to drive behaviours. To keep up to date with the Metric of the Month series, subscribe here.
About the author
Matt Burns
Related blogs
Three measurement essentials for reporting cybersecurity to the board
