The engineering team experience at Panaseer
May 17, 2021
Hiya, I’m Lucy and I work as a Full Stack Engineer at Panaseer. If you’re reading this post, you may already know a bit about the development experience at Panaseer — or perhaps you heard about our series B funding…
Either way, the aim of this post is to give some insight into the main languages, tools, and products we use on the Engineering team at Panaseer. For each of the core areas of our development process, I will give an overview of what each tech component does, the reasons we chose it, and if there are any changes planned for the future.

Join our team! We are #hiring for a number of roles across the Engineering team! If you’re interested in joining Panaseer on our growth journey and work in an environment that fosters innovation and autonomy, get in touch.
Some of the role we currently have open through Workable:
Data Engineer
Senior Data Engineer
Senior QA Engineer
Core Languages

Most of the Engineering work at Panaseer is done using one of our core languages. Across the Web-, Data- and Data Science platform, these are the languages and frameworks our engineers spend most of their time working with.
Whilst most of them have been a core part of our work for many years, we continuously evaluate new languages for opportunities to modernise our stack and take advantage of emerging technologies.
Java
We use Java 8 for most of our consumer-facing APIs. Some of our key reasons for choosing Java were:
Java is the most popular language for backend applications and therefore it is easy to find developers with Java skills
- Long-term support is available
- Large community of libraries and features
- Monitoring tool availability
- We are currently in the early stages of upgrading to Java 11. Looking to the future, our only planned changes in this area will be to keep upgrading versions as they become available.
Scala
Our data platform team uses Scala primarily for all programming needs when working with Hadoop, particularly Spark. Scala’s functional programming style lends itself well to concurrent programming and therefore can be very concise, however compared to Java it can be more challenging to find developers & the learning curve is quite steep.
TypeScript
We use Typescript in combination with Angular 11 for the majority of our Frontend work. As our Frontend codebase grew over time, the need for more structure and stricter typing made the introduction of Typescript a no-brainer.
Python
As Python is a powerful scripting language, we use it for a lot of cloud automation tasks, as the scripts tend to be relatively short & aren’t often re-used.
Python is popular with our Data Science team, due to its ability to quickly iterate scripts and the ecosystem of data science libraries that Python supports.
SQL
Our platform is focused on data and the insights we can draw from it — SQL is the front runner for achieving this. In the past, we have explored other technologies such as Graph & NoSql databases, but SQL has given us the best portability & compatibility we need when moving between technologies.
Development Platform
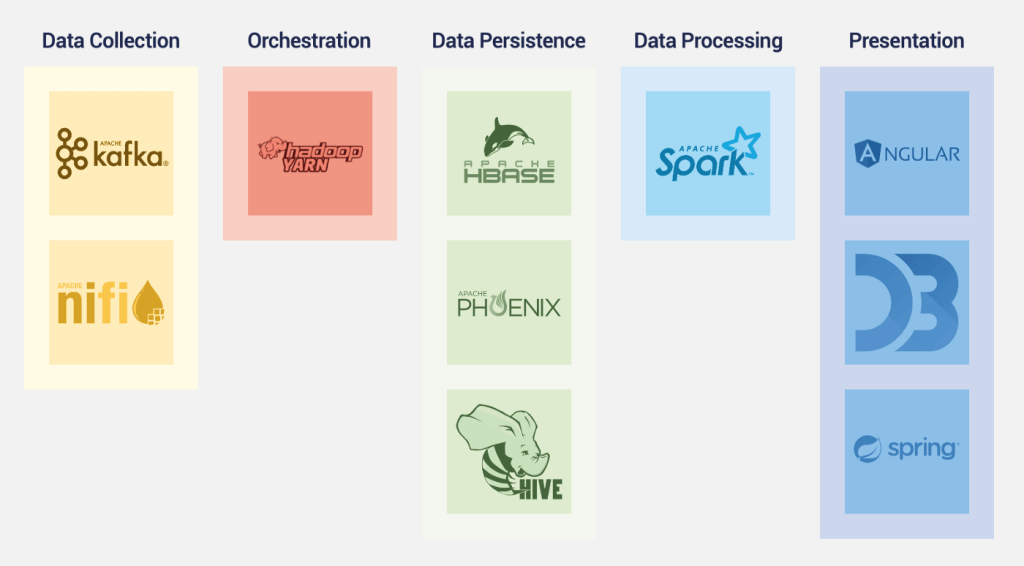
The development platform across the Web and Data stack provides structure and form to our applications.
They’ve been chosen for the performance they provide on high data volumes and application structure that enables us to scale in a stable & effective manner.
Web Platform
Angular
Angular has been our Frontend framework of choice since the beginning of Panaseer. As a large-scale enterprise application, we found ourselves in need of an opinionated framework that can support our scale early on.
Initially working with AngularJS, over time we’ve transitioned the majority of our codebase to version 11 (at the time of writing the post) — what a change that’s been.
Whilst other frameworks have emerged and risen to popularity, we find Angular continuing to satisfy our development needs at scale.
Most recently, we’ve continued to drive innovation on the Frontend codebase by introducing the Nx Monorepo framework. This will be a crucial step to support our next growth stage, both in terms of application size and Engineering team growth.
Spring
Spring is a framework, which allows you to auto-configure standalone Java applications. At Panaseer we use Spring Boot to build all our user facing APIs.
Spring Boot is a popular choice for developers using Java, as it is possible to get a production level application running quickly, without having to worry too much about configuring the application correctly and safely.
Some of the main benefits of Spring Boot are:
- It comes with embedded HTTP servers, such as Tomcat.
- There is no need for writing a lot of boilerplate code, annotations or XML configuration, as these are all included in the framework already.
- Spring allows you to easily connect with database services such as PostgreSQL and MySQL.
- Spring is an easy tool for junior developers to learn.
Data Platform
Apache NiFi
NiFi is a tool used to ingest data from multiple different sources. It can connect to a variety of sources, such as REST endpoints, log files & SQL. It has a drag and drop UI, making it easy to use and configure by both technical and non-technical teams.
Apache Kafka
Kafka is an industry standard data streaming tool. We use it as an online state store, for data that has been ingested from NiFi. It is useful for us as the ingested data gets persisted before being processed in our platform, meaning we can re-read the data in the future as well as in real-time. Like NiFi, Kafka is flexible & integrates easily with many tools.
Apache HBase
HBase is a NoSQL database, which runs on top of HDFS (a file system provided by Hadoop). It is the data layer used by our presentation API, to display results and metrics on the UI. As a NoSQL DB, it gives us the ability to do very performant random lookups and almost infinite scaling.
HBase will be replaced when we move to a fully Cloud Native solution. We are in the process of investigating the possibility of using AWS Redshift and Snowflake when that time comes.
Apache Phoenix
Phoenix is a SQL-like query engine that we use to query HBase data. It translates SQL queries into range scans and aggregations in HBase.
Whilst it looks like SQL, it only has a subset of features, meaning that the portability of the SQL that we write, is limited slightly. When we move to Cloud Native, this will also be replaced by the SQL of technologies such as AWS Redshift or Snowflake.
Apache Hive
Hive is our batch data processing layer for writing and reading data from HDFS. It also provides a SQL-like query engine and is an industry-standard tool when working with Hadoop. It is a columnar data store so is well suited for analytical queries and “big data” workflows. With the move to Cloud Native, HDFS will be replaced by Cloud storage services such as S3.
Apache Spark
Spark is a highly scalable data transformation tool. It is the industry standard choice for data transformation, as it is performant and works well with other tools. The transformation interface is similar to SQL, so familiarity with SQL means there are transferable skills when using Spark. Spark provides a level of abstraction over MapReduce and allows transformations to be easily chained together.
We are currently exploring the option of using AWS EMR which provides a more cloud native approach to Spark.
Continuous Integration

Cypress
Cypress is an E2E JavaScript testing framework, that allows us to write functional tests for our web application. As a relatively new tool, native Cypress offers some unique functionality that other more common test frameworks such as Selenium do not provide. This includes the ability to debug using dev tools inside the test run, as well as the automatic waiting for commands & assertions, which eliminates test flakiness and removes the need for boiler plate code to manage this.
When choosing Cypress, some of our core requirements were:
- The ability to mock/stub requests so we could use the tool for integration testing between our Web and API layer.
- Ability to assert our visual elements are as we expect.
- Ability to capture the screen at the point of failure to make investigation of failing tests easier.
Runnable within CircleCI.
Our initial implementation of Cypress caused some pain points — the main one being that the Cypress UI could become memory intensive and tests would take a very long time to run, often hanging and failing on timeouts causing us the need to re-run a long CI flow. Eventually, investigation into this & some restructuring of our tests ironed out the majority of these cases and we are now starting to really see the benefits of Cypress in catching UI bugs that we don’t catch during manual testing. As well as this, Cypress has excellent documentation with lots of code examples and it offers active support and has a large user community.
Going forward, we are continuing to explore ways to make our Cypress usage the most beneficial. Some current considerations are:
- Cypress Studio — a tool that generates the test code by recording user interactions with the browser whilst running through the test scenario.
- Iframe and webkit support.
Circle CI
Circle Ci has been powering our Continuous Integration and Continuous Delivery work for the last few years. The decision to go with CircleCi was based on the out-of-the-box functionality it provides including pipeline metrics that help us identify and address build, test and release bottlenecks on a continuous basis.
Gradle
Gradle is a build automation tool, used for JVM languages; we use it on both our Spring and Scala APIs. The build scripts are written in Groovy but the concepts are taken from Apache Maven & Apache Ant. However, a few of the reasons for preferring Gradle over these are:
- Less bloated scripts as they are Groovy, not XML.
- Easier to read.
- Easier to add custom build code.
However, that is not to say that Gradle is perfect. It can be a steeper learning curve than Maven or Ant & if you’re coming from an XML based build tool, the Groovy syntax can be tricky to immediately understand.
Infrastructure, Infrastructure Provisioning and Deployment
Infrastructure is the backbone of any application and the choices made by our DevOps team in this area ensure efficient and cost-effective running of our product.
Amazon Web Services
Why do we use it?
It is the largest and most established cloud provider.
Using Cloud provides a lot of flexibility and a pay as you go attitude for using compute power which ultimately reduces our own maintenance work and cost.
AWS provides managed services which shortens development time and reduces the operational overhead of running virtual machines.
AWS is great in many ways, it allows automation, a large amount of PAYG services and will keep the lights on for you most of the time.
What do we use it for?
We use their services to host our infrastructure using EC2 for virtual machines and Fargate for hosting containers in a serverless framework. The Organisations service is used to create and maintain our account structure and Lambda service to automate tasks as well as triggering deployments. Other AWS services are used as well such as IAM, Route 53, S3, and many more.
Are there any downsides?
Cost aside, the only other downside is their way of implementing their services in rigid ways. This can sometimes make it difficult to interact with them and ugly workarounds are needed.
Terraform
Terraform is infrastructure as code and can be used to deploy infrastructure but also software on a multitude of platforms. At Panaseer, we only use it to manage our AWS infrastructure.
We chose Terraform, as at the time only two tools were “mature enough” to manage IaC in AWS: CloudFormation (AWS) and Terraform (Hashicorp). Terraform allows far more flexibility than CloudFormation does and more detailed change plan before committing to the changes. Terraform’s release cycle is quite fast-paced but they are mostly trying to improve the current offering as it is still rather immature, sometimes with bugs which ought not to be there.
We have a bit of a love/hate relationship with Terraform. We love its general flexibility, the vast amount of work we can achieve with it, its speed of execution and the amount of detail it provides before making changes. However, since the product is so immature, it has resulted in a huge amount of code duplication — Terraform lacks support for a lot of things (mostly looping through). There are a lot of bugs and working around them can be very painful, as can working around the lack of features.
Ansible
Ansible is a configuration management tool, which helps us deploy changes to virtual machines by ensuring the process is repeatable and idempotent. Writing Ansible code is quite close to a pseudo language which makes it easier to use and set up. We like its simplicity, the fact it’s agent-less and usually quite reliable. Ansible bugs are quite rare and usually easy to workaround.
There are no active plans to change our use of Ansible, however at some point it wont be required because we plan to move to a container based architecture
Since I joined Panaseer, just over a year ago, whilst the core components of our engineering experience have remained the same, there has been a continuous drive to explore new tools and technologies. A notable example of this is the improvement of the CI flow for our web application before deployment. The introduction of Storybook (a UI component builder), Percy (a visual diff testing tool) as well as the vast improvement and extension of our Cypress test unit, are all motives that have been explored then adopted in the past year, making our web client more robust and reliable.
In my opinion, this allows for developers to gain a solid understanding of some very common industry tools (e.g. Angular and Spring), but also to experiment with new tools and tech as it is released and to know that there is always room for change and growth, in order to enhance either our application or team performance.
Thanks for reading!
If you’ve reached the end of this post, thanks for reading & I hope it has been helpful in better understanding our development choices.
Find us on Twitter @panaseer or take a look at some of our other publications here.